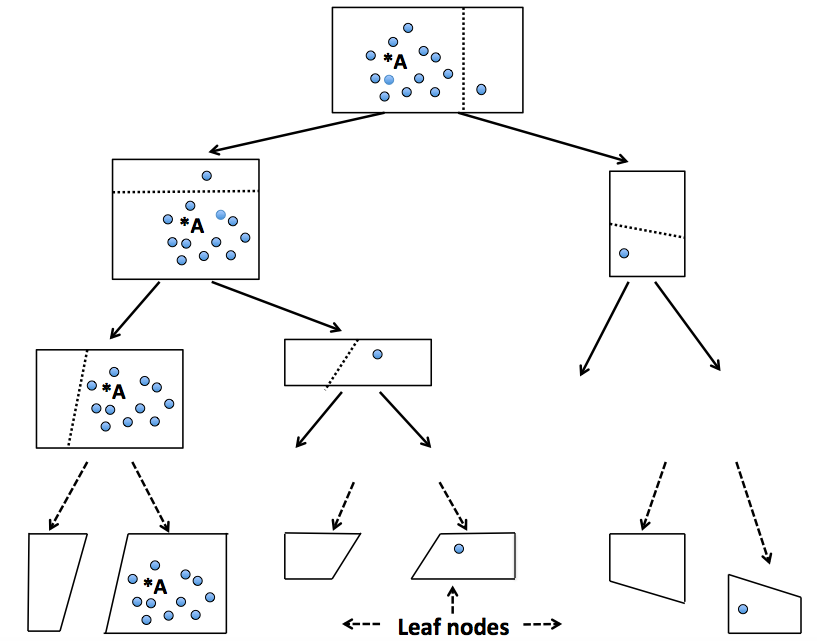
Random projection forests
Random projection forests (rpForests) is a versatile tool for data mining, statistical inference and machine learning. It was inspired by our long term interests in randomized tree ensemble methodology, including Random Forests, random project trees as ingredients in fast computations (e.g., fast approximate spectral clustering), as well as clustering ensemble based on randomized feature pursuits (e.g., Cluster Forests).
|
rpForests is an ensemble of random projection trees with possible selection of random projections. The probability of mis-separation of nearby points decreases exponentially fast when the number of trees increases. rpForests has a very low computational complexity as inherited from trees. The ensemble nature of rpForests makes it easy to run in parallel on multicore or clustered computers. Our theory on the basic implementation can be used to refine the choice of random projections in the growth of trees.
|
Desirable features about rpForests:
- rpForests combines the power of ensemble and the flexibility of trees;
- Computationally efficient and can easily run in parallel on multicore or clustered computers;
- Probability of mis-separating nearby points decreases exponentially fast;
- Can be used to discover locality in the data, with applications such as
- Large scale k-nearest neighbor search
- Deep representation learning (generating cluster-aware features).
- Data driven similarity kernel and clustering.
- R implementation Download (coming soon)
- Example datasets (from UC Irvine Machine Learning Repository)
You are welcome to send questions, comments, suggestions, or to report bugs to us. Thank you!
Citation
[1] D. Yan, Y. Wang, J. Wang, H. Wang and Z. Li.
K-nearest neighbor search by random projection forests.
IEEE Transactions on Big Data, Vol 7(1), 147-157, 2021 (online since March 2019). Preliminary version appeared in
IEEE International Conference on Big Data, 4775-4781, 2018.
arXiv:1812.11689
[2] D. Yan, T. W. Randolph, J. Zou and P. Gong.
Incorporating deep features in the analysis of TMA images.
Statistics and Its Interface, Vol 12(2), 283-293, 2019.
arXiv:1812.00887
[3] D. Yan, S. Gu, Y. Xu and Z. Qin.
Similarity kernel and clustering via random projection forests.
arXiv:1908.10506
[4] K. Wang, X. Bian, P. Liu and D. Yan.
DC2: A divide-and-conquer algorithm for large scale kernel learning with application to clustering.
IEEE International Conference on Big Data, 5603-5610, 2019.
arXiv:1911.06944
Video
[
cmsa2019]