- Distortion minimizing local transformation on the data to get a small set of representative points which preserve its structure.
- Spectral clustering on the set of representative points.
- Recovery of the cluster membership for all data points by their correspondence to the representative points.
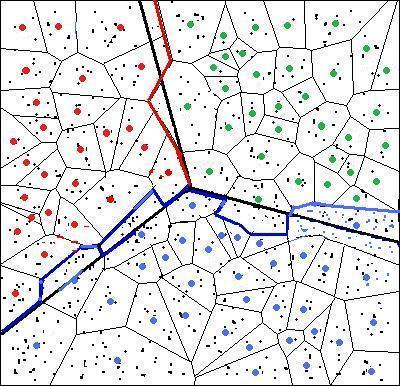
|
Since the distortion minimizing local transformation can be computed with fast
procedures while the
expensive spectral clustering is only performed on the
representative points, large speedup can be achieved. Our theory predicts
that if the distortion resulted from the data "compression" is small, then
algorithms
implemented within our framework will incur very little loss in clustering
"accuracy". As it turns out, only points near the class boundary may be impacted; but such points carry only a small fraction of the total number of points if the decision boundary is not terribly complicated so the loss in "accuracy" will be very small for methods under our framework. |
Currently we have two concrete implementations for distortion
minimizing local transformation, one based on K-means clustering and the other
on random projection trees. These two are chosen for their favorable empirical
computational efficiency and the simplicity of their implementation. Evidently
other approaches can be adopted if the resulting distortion can be
made small. For more details on the general framework, please refer to
[1]. The linear computational complexity of these two implementations makes it highly desirable to apply such a framework to the spectral clustering of big data.
It is worthwhile to note that, our algorithmic framework and the associated perturbation analysis extends far beyond spectral clustering as a general recipe for the fast approximate computing of many computation-intensive algorithms, for instance, principal component analysis, kernel machine-based algorithms, and semi-supervised learning etc.
- R implementation Download (UNIX/Linux, Windows)
- This implementation is completely self-contained except a reference to standard R library 'MASS'.
- Example datasets (from UC Irvine Machine Learning Repository) Download
- You are welcome to send questions, comments, suggestions, or to report bugs to us. Thank you!
Citation
[1] D. Yan, L. Huang and M. I. Jordan. Fast approximate spectral clustering. 15th ACM Conference on Knowledge Discovery and Data Mining (SIGKDD), Paris, France, 907-916, 2009. [Long version].
Slides [kdd2009] Video [kdd2009]