 |
Cost is often a concern for statistics or machine learning algorithms.
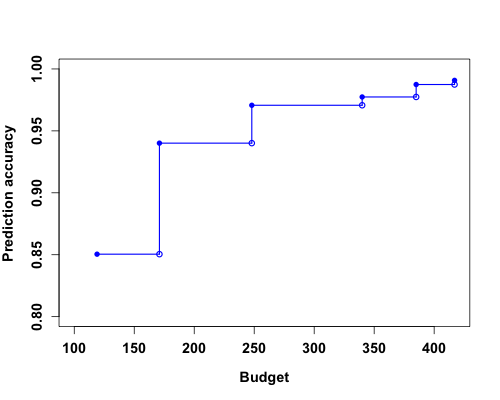
In many applications, such as e-commerce or manufacturing systems etc, the deployment cost for data-driven algorithms may be expensive due to the need of a continuous supply of large data. For example, the collection, purchase, storage or maintenance of data all incur a cost. Such costs quickly shrink the profit margin of large scale data-driven applications. We propose an efficient algorithm that is able to generate a cost schedule such that, for any given budget, it would suggest variables to use for near optimal model performance while the total cost of data is under the budget.
|
Citation
[1] R. Ming, H. Xu, S. Gibbs, D. Yan and M. Shao. A deep neural network based approach to building budget-constrained models for big data analysis. The 17th International Conference on Data Science (ICDATA), Las Vegas, Nevada, USA, July 26-29, 2021.